Deep Reinforcement Learning (DRL) on Legged Robots
As part of my research as SS Lab, I work to develop policies that can help a legged robot walk. My thesis focuses on training policies that can allow a legged robot to walk and fly based on what terrain it sees around it. I have also developed policies that can do complex acrobatics like a backflip on a quadruped, and am currently working on a policy that allows Spot to play badminton with a human player!
Husky-Beta Terrain-Aware Multimodal RL

The main robot I work on in my lab is the Husky-Beta multimodal quadruped. It has a Jetson Orin Nano on board as the computer, capable of running RL policies in real time at 250 Hz. It also uses Dynamixel Servos to actuate the joints. Shown here is the robot in walk and flight phase. It is able to switch between these seamlessly using the stand that is attached to the body.
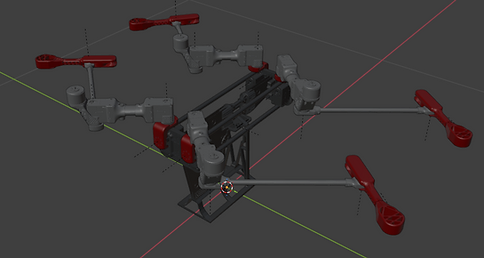
Since the robot should be able to fly, the Dynamixels were the best choice, but they limit the robot to only position control while walking. Meaning torque commanded techniques like MPC will not work on the robot. As a result, I am using a controls interleaved RL policy that will do position control and track swing leg foot targets to walk and reject disturbances.
Shown on the right are the parts mounted on the robot, along with the communication logic between each component.


Reinforcement Learning (RL) is a reward/penalty guided learning process where an agent takes actions in an environment and gets some reward on how good/bad that action is. Every action a takes it to a new state s and new observation o, and gives a reward r, so we have a state-action-reward-future state scheme to propagate the environment.
The goal is to take actions that will maximize the expected reward over time
The overview of the multimodal controller is shown below. With knowledge of terrain around the robot, and a goal pose to reach, a high level policy is able to learn what velocity commands and mode to send to the low level controllers. It can pick mode 0, which will run the walk policy, and supply the velocity command to track, or pick mode 3, which is the flight controller, and again give velocities such that the robot flies over gaps in terrain or to unreachable areas with a walk only policy.
The benefit of using RL here is that the policy learns when to switch from walk to flight and vice versa instead of a user having to account for all edge cases and code for it.

For the walk controller, I am using a raibert heuristic to determine foot targets. Then, this target and a contact schedule is fed in as an observation to the robot at each state. The policy uses the observations and the reward signals to determine what joint position target to give. In this way, the policy learns to walk and infer the trajectory to get from where the foot is currently to the foot target, and also move the base to the desired velocity. The RL formulation for the robot is shown here.

The results from the training are shown below. I show a fully RL walk policy on the left, and then a raibert foot target guided RL policy on the right. Both policies are capable of disturbance rejection, walking, and following the desired velocity. The benefit of this is that the RL policy learns emergent behaviors for friction or other model mismatches from sim-to-real that otherwise will be very difficult to code with classical control.


The final HLP results are shown below. It can be seen that the robot is able to fly over obstacles by entering flight mode, and land when it gets to the goal pose, finishing the navigation behavior. The red dots are the scans of the terrain it sees, acting as an elevation map, which allows the policy to learn anticipation of obstacles. For the flight controller, I apply a force and torque to the base based on error with the desired velocity and actual velocity. This way, a simple controller allows the robot to fly in simulation. On the real robot, the PX4 flight controller will handle flight, so there is no need to train a policy or write any more complex code for this.



Unitree Go2 RL Walking
Again, just like the Husky-b RL Walk, I also trained and deployed a fully RL policy on the Unitree Go2 quadruped. The main challenge here was the linear velocity. Since Unitree doesn't allow us to develop our own software and use their state estimator at the same time, I had to train a policy without linear velocity as an observation. To account for this, I buffer 5 timesteps of body angular velocity, gravity projection, and joint positions. This allows the policy to infer linear velocity and obtain close enough performance to a policy that was trained with linear velocity.

The results from the training are shown below. It was not as robust, but still able to withstand some disturbances and walk to the given velocity command. It will seem "drunk" because the lack of a linear velocity observation makes it hard for the robot to follow the linear velocity command.



Unitree Go2 Acrobatics: Backflip
With RL, I was also able to train some highly dynamic behaviors like a backflip on the Go2. I use blender to first create the reference trajectory to track. With a few keyframes, Blender is automatically able to interpolate what happens between. It also perform Inverse Kinematics automatically in case one wants to move just the end effector position over time.
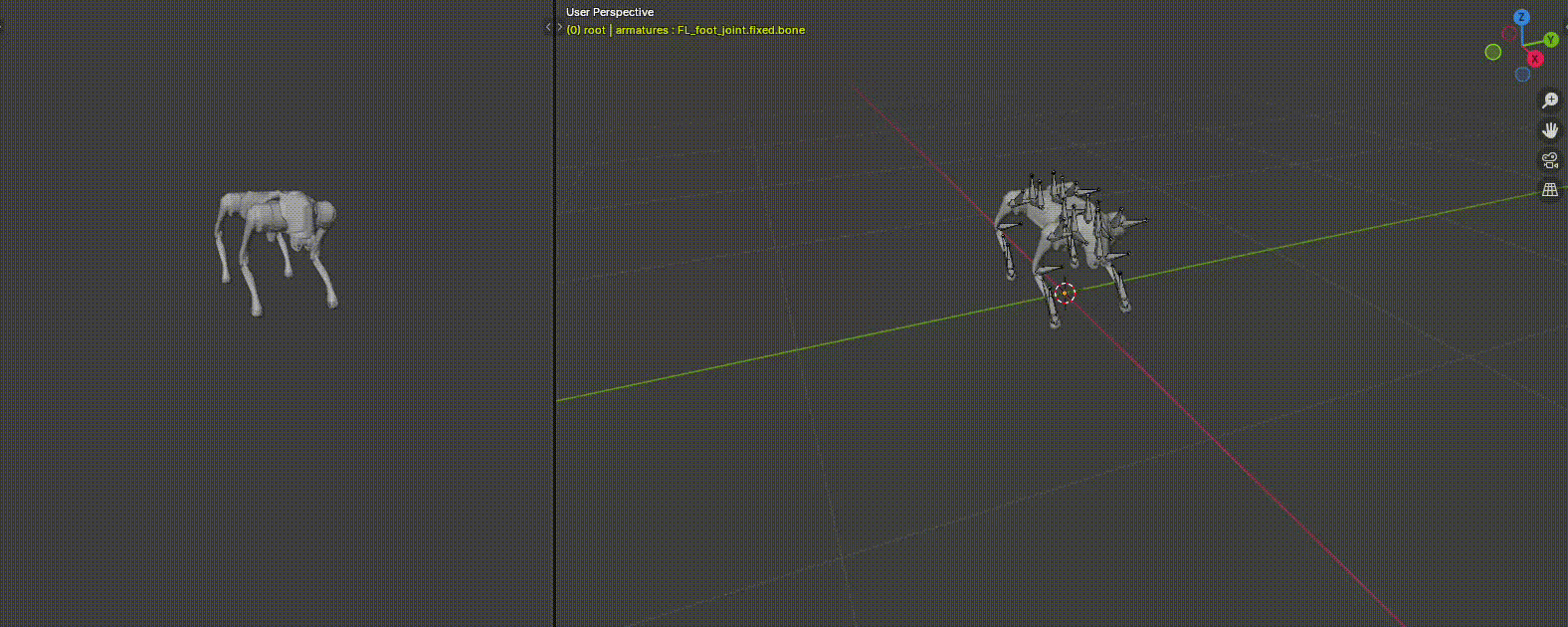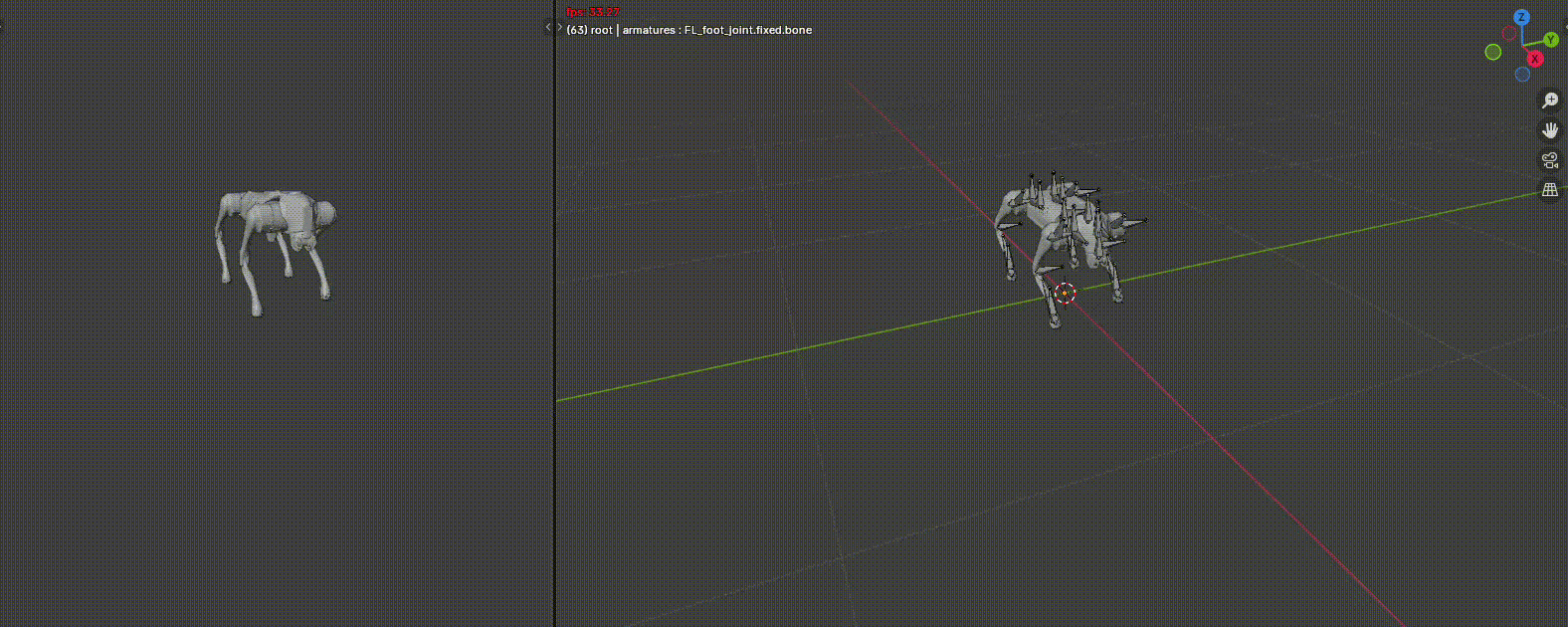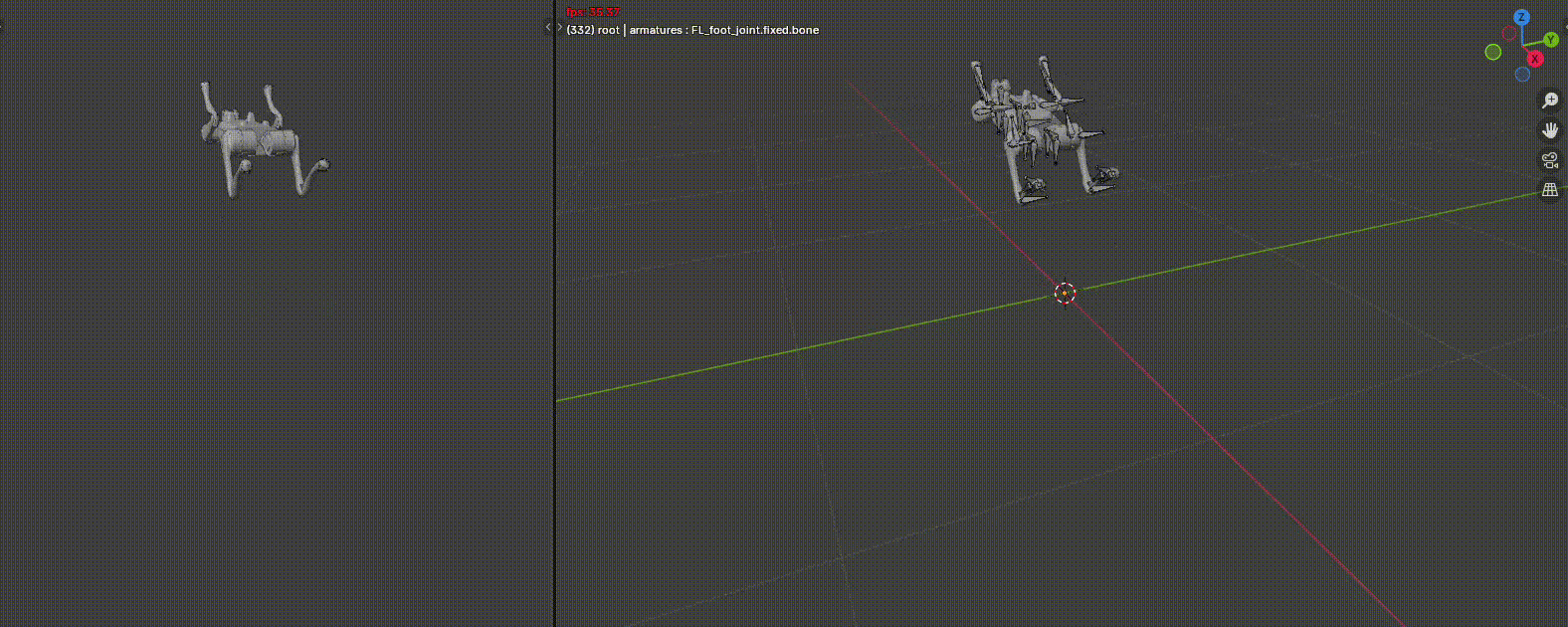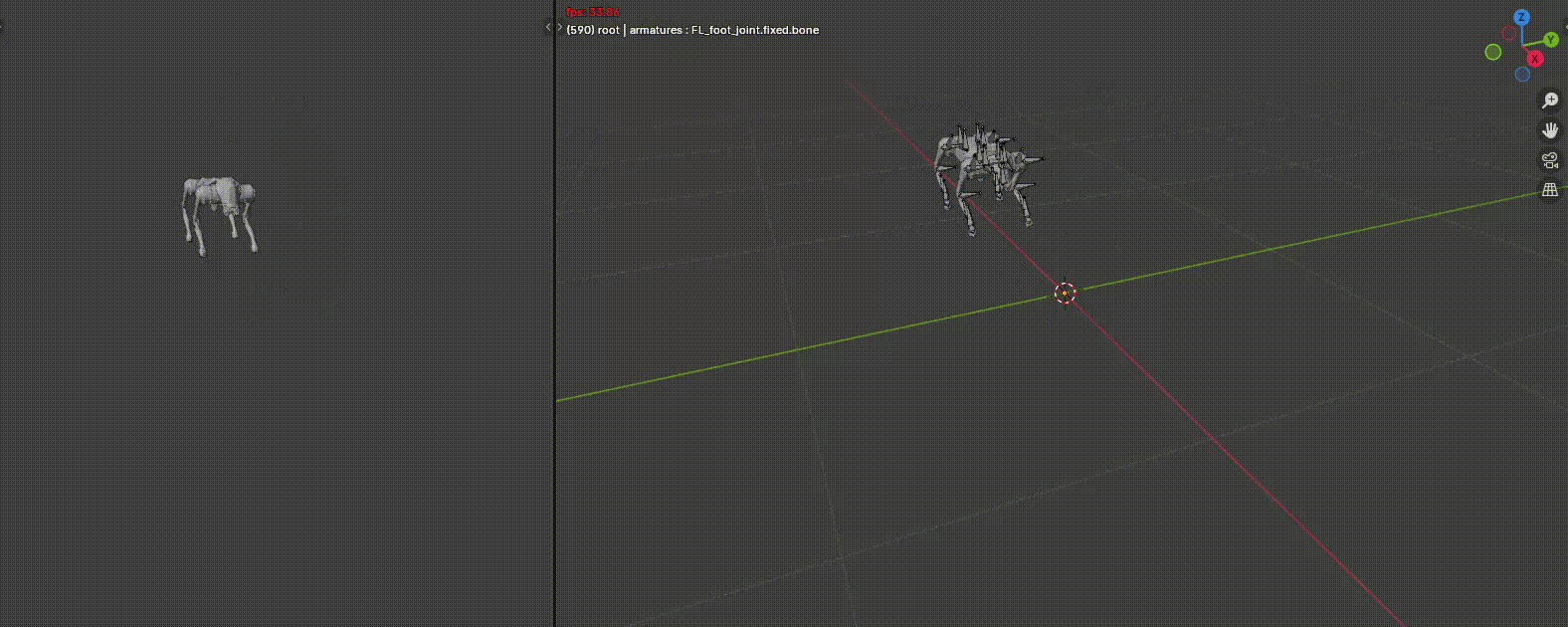

Then, I train that reference tracking in IsaacLab, where residual RL is used to add corrections according to the physics, and any model mismatches. Finally, it is put on hardware. The reference joint positions and body state is fed as an observation to the policy and a reward signal is generated. I show the results of the trained policy here.
To speed training up, I add in a wrench assist which will apply a force and torque to keep up with the reference at first. Over time, it will decay to no assist and the policy takes over fully. The red arrows you see appear sometimes is the wrench assist magnitude.
Finally, it is put on hardware. The reference joint positions and body state is fed as an observation to the policy and a reward signal is generated. I show the results of the trained policy here. There are still some sim-to-real issues here with the joint dynamics, but these can be trivially ironed out with further training.
Additionally, with this approach, more acrobatic policies like handstand, barrel roll, and front flip can be trained on the quadruped.
